Paper Link –> show, attend and tell: neural image caption generation with visual attention
Summary:
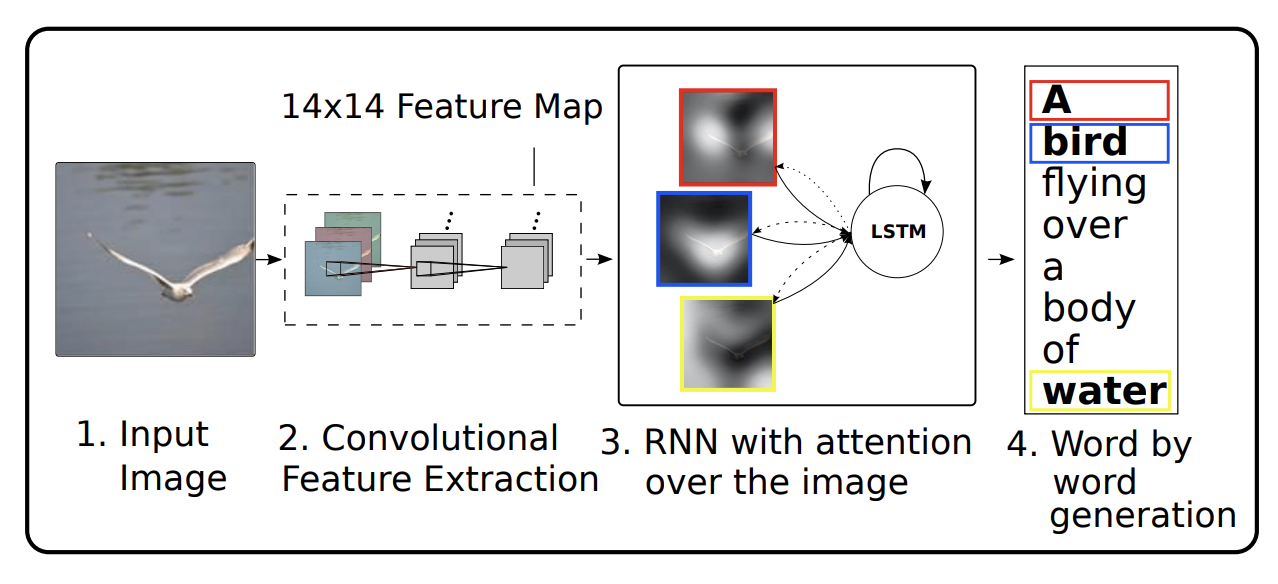
The authors in this paper present a model that takes advantage of visual and language processing to generate captions for images. The task of image captioning is considered a challenging problem in the field of artificial intelligence, as it requires the model to not only detect the objects present in the image but also to understand their relationships and generate corresponding words that accurately describe the image’s content. Previous methods have used neural networks and recurrent architectures with object detectors to generate captions. However, the authors in this paper propose an attention framework in the encoder(CNN-VGG) and decoder(LSTM) approach that learns the latent alignments between words and images from scratch, which is quite interesting. Also, this framework enables the model to visualize the most relevant regions of the image it attends to as it generates the caption.
The authors introduced soft (relative importance to the part of the image) and hard(attention to certain isolated parts of the image) attention, significantly improving the model’s performance on three benchmark datasets. Overall, this paper presents a major advance in the field of image captioning and sets the stage for further research in this area.
Strong Points:
- The performance of the single model with attention was able to outperform the previous methods using an ensemble of models in terms of BLUE and METEOR scores.
- The visualization of the captions generation was so interesting as how the model attends to the important region as most of the machine learning models are black boxes, and understanding where and why it is failing might be a good foundation block for more interesting follow-up works.
- The authors used a simple writing style with sufficient background work to understand this work. Also, the explanations are conveyed well through appropriate supporting examples, equations, diagrams, and visual cues that help the readers understand better. Also, the code base released.
Weak Points:
- The authors fail to mention the significance of the hyperparameters rand e in their paper, which could be value-adding for readers to comprehend this approach fully to incorporate in their future research work.
- Another important aspect is the runtime comparison, as the paper doesn’t use an object detector. How better is it in terms of training time and inference time?
- The paper hasn’t mentioned the limitation and future direction.
Reflections:
- This seems like a solid paper to work on the Explainable Artificial Intelligence as most of the AI models are black boxes, having an inference and understanding plays a key role
- Exploring attention in image & text-based architectures to explore the benefits of attention further.
Most interesting thought:
- Using attention: We calculate the weights for each annotation vector
- Soft Attention: Higher value to the part of the picture having higher attention use a weighted average to have relative importance.
- Hard Attention: Use one annotation vector which a high value to the LSTM so that only the most relevant aspect of the image is in the context vector. Remaining ignored.
This page was last updated at 2024-12-21 01:09.